Code Is Still Documentation. Docs Can Finally Keep Up.
The real problem was never docs. It was drift.
“Code is the documentation.” Every engineer has heard it. Most of us have said it. It gets cited in interviews, tech talks, and the README of every new project as if it were a first-principles position arrived at through careful thought.
It wasn’t. Here’s what actually happened: we used to write prose documentation. It went stale. Keeping it fresh cost more, in time and attention, than the docs were worth when stale. So we stopped writing them and said readable code is enough.
That’s not a principle. That’s a coping mechanism for a labour-economics failure we never quite admitted was a failure.
The question this post answers is simple: what if that labour cost weren’t there anymore?

The use cases we always wanted and never really got
Go through the list of things “keep current docs” would actually buy you. These are not new use cases. Every engineering org has wanted these for decades:
- Onboarding — you wanted current architecture docs so a new hire could read their way into the system. You settled for “pair with a senior engineer for two weeks.”
- Knowledge transfer — you wanted exit notes that would still be useful the week after someone left. You settled for a half-remembered wiki page and a Slack search that goes three years deep.
- Planning and design review — you wanted a current description of what already exists, so the design meeting could start from facts rather than memory. You settled for a guessing game during the meeting, and a Jira ticket to “document after.”
- Status reporting — you wanted written status current enough to be believed, which makes async collaboration viable. You settled for synchronous ceremonies every morning that re-establish shared state out loud.
- Stakeholder comms — you wanted a non-engineering reader to be able to open a module description and understand roughly what it does. You settled for “let me set up a sync.”
Each settling was a small failure we learned to accept. Individually they felt minor — five or ten minutes a week, a meeting that could have been an email, a confused new hire catching up eventually. Collectively the cost is enormous, but it doesn’t show up on any one team’s dashboard. That’s why it was never prioritised. There was never a moment where the pain got sharp enough to force the fix.

What changed: the labour economics collapsed
Here’s what changed. Claude Code sub-agents can regenerate prose documentation from current code on demand, in minutes rather than weeks, at a marginal cost close to zero. A sub-agent dispatched with the code as input produces a description of current behaviour. Run it again after the next edit and the description updates. The artefact is disposable — you don’t maintain it, you regenerate it.
This isn’t the hand-wavy “AI writes your docs for you” that everyone’s been selling since 2023. It’s a specific process: distinct from the edit, distinct from the chat, executed against the code as it exists right now.
The old blocker for prose documentation was never “what should it say.” We’ve always known what docs should say. The blocker was “who’s got four hours a week to keep it current.” That blocker is gone.
Fresh docs become structurally possible for the first time. The old use cases from the last section become reachable. And one new use case emerges — one that didn’t exist before, because it only makes sense when agents are the ones writing the code.
The new use case — agent verification
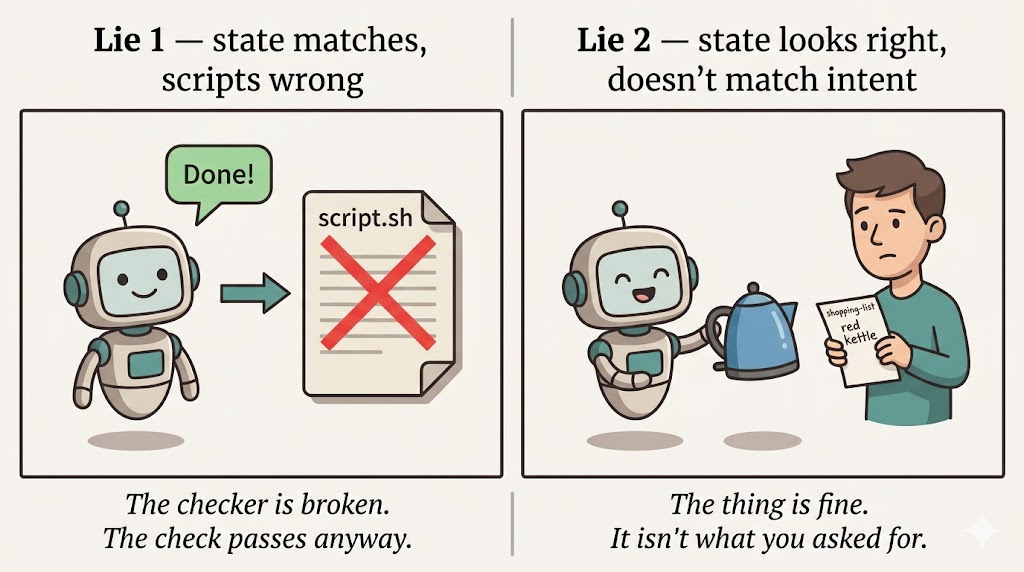
Agents say “done.” Most of the time they mean done-ish. Two specific lies sit behind that word:
- Lie 1 — The state matches what you asked, but the thing creating that state is wrong. Scripts passed, logs look clean, but the scripts themselves are broken.
- Lie 2 — The state looks right, but it doesn’t match the intent behind your request. Wrong thing built, looks fine, nothing to trip over.
Readable code catches neither. Tests catch the first if you wrote them for the right thing, which is itself a trust question about the agent that wrote the tests. Docs generated from the code catch both earlier and cheaper, for a specific reason: they describe behaviour derived from the code, not claims derived from the chat. The code is what the agent actually did. The chat is what the agent said it did. Those are not always the same document.
The war story
I was working on a system configuration task and told the agent, explicitly, to verify each step via scripts — not by claiming success, but by running something that would tell us the truth. The agent did some of that: it wrote scripts and ran them. It also did a handful of manual-type actions and confirmed them in prose.
Everything “passed.” The system state matched what I expected. The scripts exited 0. The agent reported done.
Then I read the generated docs. The docs described what the scripts were actually checking, which was not what I’d asked them to check. They were passing on the wrong condition. The system looked correct because the scripts couldn’t tell it wasn’t.
Testing on a clean system would eventually have caught it — the tests would have failed on a fresh machine, for the right reason. But the docs caught it earlier, at read time, before any test was run.
What’s being caught here isn’t code correctness in the usual sense. It’s a verification-of-verification failure: the thing I’d told the agent to serve as proof was itself wrong. Only a different signal — docs derived from code, read in a clean context — surfaced the gap.
Clean system, clean context
The war story reveals a parallel worth naming:
Testing requires a clean system. Doc generation requires a clean context.

The reason is the same in both cases. Contamination hides failures. A test run on a dirty system can pass for reasons that have nothing to do with the code. A doc-gen run contaminated by the agent’s own reassurances — whether literally in the prompt or still sitting in your head — mirrors the agent’s story rather than the code’s behaviour. Regenerate from a fresh context and the feedback loop breaks.
Claude Code sub-agents make this a property of the architecture, not a discipline you have to remember. A sub-agent starts with a fresh context window and only sees what you hand it. Pass it the code; don’t pass it the conversation. Clean context is the default.
This is how you catch Lie 2. Lie 1 is structural — the bad scripts exist regardless of context, and the docs reveal them because the docs describe the scripts, not the scripts’ claims. Lie 2 is perceptual — the state looks right if you’re primed to see it looking right. Clean context removes the priming.
In practice — Claude Code sub-agents + custom workflow
Here’s the shape of the loop as I run it. Tooling: Claude Code sub-agents, dispatched via a custom workflow. The setup is less interesting than the structure, so I’ll stick to the structure.
Trigger. Doc generation fires after an edit-agent finishes a meaningful change — typically post-edit as a sub-agent invocation, before I approve anything. Some teams will want it pre-merge instead. Both work; the point is that doc generation is a distinct step from the edit itself, not interleaved with it.
Dispatch. The edit-agent completes. A separate sub-agent is dispatched with the code as input — not the conversation, not the diff, not the agent’s summary of what it did. The code. The sub-agent returns a prose description of current behaviour. That’s it.
Read for congruence, not correctness. You’re not checking whether the code is right. That’s what tests are for, and it’s a different question. You’re checking whether the description matches what you remember asking for. Congruence is the word I keep coming back to. Does the prose on my screen describe the feature I think I asked for?
Believe the docs. Here’s the failure signal, stated plainly: the description reads fluently, in confident prose, but describes a system you don’t recognise. When that happens, believe the docs. The docs were derived from the code. Your memory of what you asked for was derived from the chat. When they diverge, the code wins.
One more small note. This catches drift between one agent edit and the next — the new-era version of the doc-drift problem. The old-era version (humans writing, humans forgetting to update) is also dead here, for the same reason: the humans aren’t the bottleneck anymore.
Code is still the source of truth. Readable code is still the floor. What changed isn’t the role of code — it’s that prose docs can finally sit alongside it without rotting overnight.
Once they can, they earn back all the jobs they were supposed to do. Onboarding. Knowledge transfer. Planning. Status reporting. Async collab. The old use cases we quietly settled without are suddenly reachable. And one new use case — catching agents in their polite, confident, wrong-but-plausible “done” — comes free with the loop.
The previous post asked what standup is actually protecting. This one answers part of it: for a lot of teams, the standup was protecting us from stale written status. We don’t need that protection anymore.
Your docs are only as honest as the context they were generated from. Keep the context clean, and the docs will tell you the truth — including the truths the agent would rather not mention.